
在过去的几年中,人工智能技术已成为推动各行各业数字化的关键力量。对于商业智能领域,人工智能大模型的引入不仅可以降低业务人员的使用门槛,还能快速实现预测性分析和自动化洞察,帮助企业更快和更准确的做出决策。

此次vividime V10.2的重磅更新,不单是在人工智能大模型的结合上,还在数据模型、指标服务、集群管控、报告应用、分享协同、分析计算等方面有重大提升。
ChatGPT引爆了一场人工智能的技术。一个显著标志就是它降低了各种工具的使用门槛,同时对BI的交互(Interactivity)也起到了积极的作用。以往我们通过拖拽加上所见即所得的方式大大降低了业务用户分析数据的门槛,而现在通过文字对话或语音即可探查数据结果,让更多的业务用户使用BI变成了可能,也大大提高了数据分析师和数据科学家的分析效率。另外,ChatGPT可以让我们对数据做更多更深层次的洞察(Insight),让我们了解发生了什么,为什么发生,以及我们应该采取怎样的决策。永洪科技旗下的vividime Copilot作为自主研发的AI大模型,致力于聚焦在如何帮助业务用户用数据、洞察数据背后的价值。在V10.2上我们利用Copilot对交互和洞察进行了双重提升,并在接下来的版本中会持续增强。
凭借Copilot的强大自然语言互动分析能力,仅需口头提问,即可瞬时获取详尽数据分析结果,告别繁复操作。并支持丰富的数据分析能力,从分析汇总、筛选、排序到TopN、同环比分析计算,均可随意提问。支持持续对话,精准理解上下文意图。问答结果支持二次加工,助力用户迅速整理分析结果,大幅度提升报告制作效率。
能力强大,支持语音提问、多轮对话、数据解读、历史及热门搜索,还能够与报告打通,支持二次编辑添加到报告中,辅助报告制作。
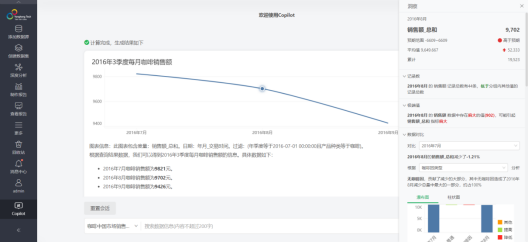
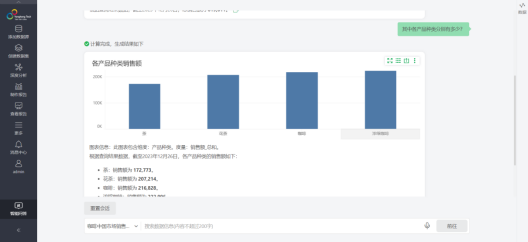
典型场景:销售团队希望快速了解各地区、各时间段的产品销售业绩,只需通过Copilot提问,即可快速生成可视化图表,展现详尽的数据概览。
SQL解释,提供深入浅出的SQL语句解析,赋予用户对查询逻辑的瞬间领悟力,增强SQL编写与维护环节的工作效能。


自然语言转SQL,拥有强大的自然语言到SQL的转化技术,使得非技术人员也能轻松运用日常对话方式构建复杂的SQL查询。
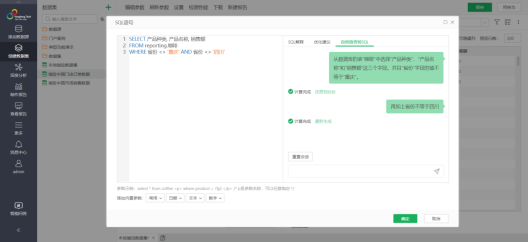
典型场景:数据分析师在整理数据时,并不擅长编写复杂的SQL查询。利用永洪AI的智能SQL功能,将自然语言提问转化为了高效的SQL查询语句,并给出SQL优化建议。
通过大模型能力,对数据进行加工处理。包括智能翻译函数translateAI,智能分类函数classifyAI,个性化任务函数taskAI,助力用户在数据治理、数据展示、电子表格等地方对数据进行快速加工。

典型场景:数据分析师在处理大量客户评论时,借助translateAI和classifyAI可以轻松翻译并分类评价内容,进而提取关键信息。
智能洞察,是我们全新推出的一项性业务分析功能。它运用先进的算法与大数据分析技术,帮助企业轻松发现业务数据增长与减少的深层次原因,从而制定更为精准的市场策略,实现业务的高速增长。
高效洞察:智能洞察大大简化了数据过滤和图表分析的过程,让用户能够快速把握数据变化趋势,为决策赢得宝贵时间。
全面报告:无论是制作报告还是查看报告,智能洞察都能提供详尽的数据分析报告,让用户对业务数据有更为全面的了解。
分析:智能洞察支持多种聚合类型,包括总和、计数、平均等,用户可根据需要灵活选择,进行度、深层次的数据分析。
数据概况:一键呈现数据维度信息、度量信息、预期范围、平均值及累计值,让用户轻松掌握数据全貌。

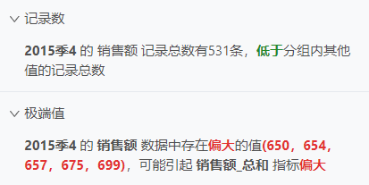
记录数分析:智能洞察能够分析数据点在数据中的记录条数,并与其他数据点进行比较,帮助用户发现数据中的异常点。
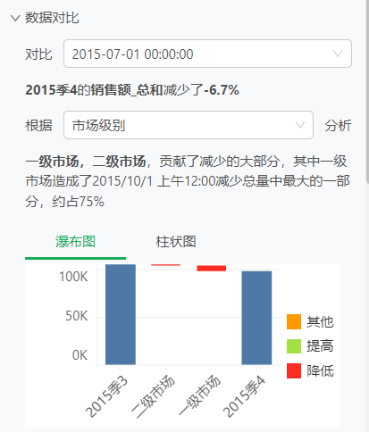
数据对比:支持用户自定义对比数据点和维度,通过瀑布图、堆积柱图、散点图等多种形式直观展示数据对比结果。
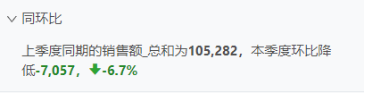
同环比分析:智能洞察可根据用户所选分析数据点,自动计算相关同环比信息,帮助用户快速把握市场趋势。
数据因素与关键因素分析:依据数据集中的维度计算占比分析,并以饼图形式展示,同时分析增长(降低)的关键因素,为用户提供决策支持。
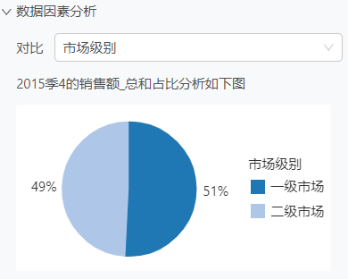
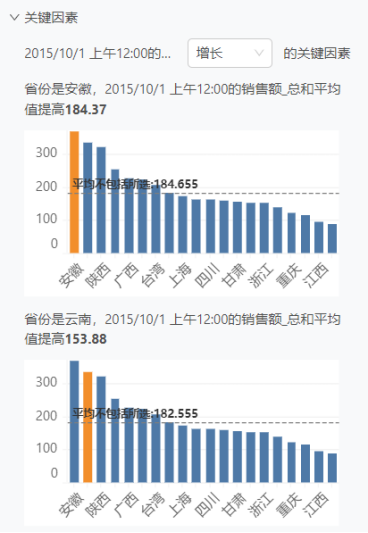
智能洞察适用于各类企业,无论是售前、销售还是客户部门,都能从中受益。售前部门可利用智能洞察分析潜在客户的行为和需求,制定更为精准的营销策略;销售部门可通过智能洞察掌握市场动态,优化销售策略,提升销售业绩;客户部门则可通过智能洞察了解客户反馈和需求,提升客户满意度和忠诚度。
在多数业务数据分析场景下,分析所需要的字段往往分散在多张表中,,推荐做法是IT工程师建好基于用户数据权限过滤的SQL数据集,通过自服务数据集进行自助式加工。由此存在的问题是用户需要花费大量的时间与精力对多张表的数据整合处理,以及合并完成后对数据正确性校验。我们就以两张表举例:
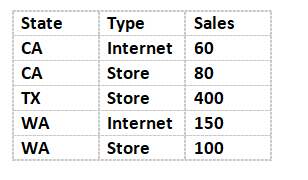
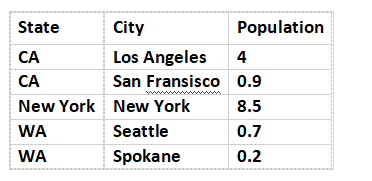
如果想看各State的销量和人口数,之前我们的想法是通过自服务数据集将两张表合并。由于State为TX和New York的数据在对方的表里不存在,为了保证数据的完整性,需要将联接方式改成外部连接。将State通过计算列合并之后得到如下数据结果:
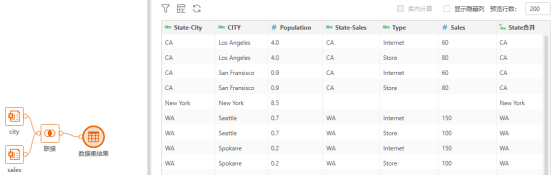
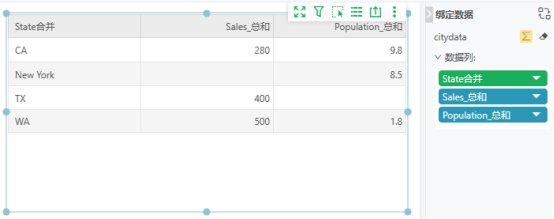
在实际的分析场景中,数据分散在各个表内,两张表的数据分析在实际场景下既要考虑数据完整性,又要考虑数据正确性,假设引入多张维度表和多张事实表,将会更加复杂和混乱。
而我们通过数据模型可以轻松解决上述问题,将相同或不同主题对应的表全部添加到一个模型中,通过简单的关系指定即可应对多变的分析需求和免去痛苦的数据校对。
在建立模型时,我们只需要拖拽sales表的State字段到city表的State上,自动形成多对多的关系,构建好一个数据模型,在实际的创建的过程中无需再考虑表的关联方式。
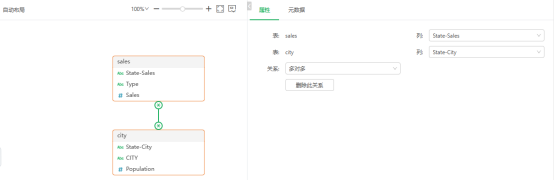
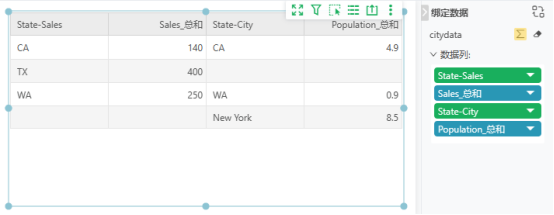
在数据模型构建中,并不会将所有建立关系的表都进行关联查询,而是在执行时,根据组件上使用的数据按需获取数据,和根据组件绑定的数据来推测节点的关联方式。
支持跨表绑定,跨表汇总计算字段,用户可以根据需求自由使用模型上的字段进行分析,不用担心数据会出错。
模型支持一对一、一对多、多对一、多对多关系,构建星型模型、雪花模型、度表多事实表模型、多事实表模型。
支持跨源建立模型,可以将不同源的表通过模型建立关系,之后在模型里将各表的数据抽取到数据集市VooltDB中,再使用模型时变成同源计算。
新版本提供一站式的可视化运维界面,当一个企业存在多个物理隔离的集群时,可以查看每个集群各个节点的状态,并且支持在该页面进行版本管理、在线换Jar包、在线回滚、在线重启。在大规模数据处理、高可用性服务、分布式存储等的多集群场景下,它可以提高系统的可靠性、性能和可扩展性,确保业务的连续性和稳定性。
支持添加集群,并对集群和集群下的单个节点进行启动,停止、重启、编辑、删除,刷新,支持上传,替换、删除产品Jar。
江南体育官网下载